 |
Code Examples
A repository of 155 code examples for BeepBeep
|
|
Code Examples
A repository of 155 code examples for BeepBeep
|
Create clusters over the distribution of symbols in a set of input streams. More...
Static Public Member Functions | |
| static void | main (String[] args) throws FunctionException |
Create clusters over the distribution of symbols in a set of input streams.
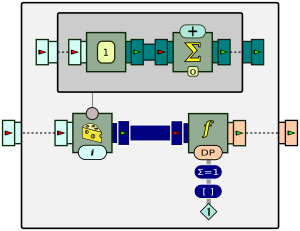
In this example, input traces are made of symbols a and b. A set of seven such traces is located in the file strings-1.csv. For each of these traces, the pattern processor β computes a feature vector made of two numbers, corresponding to the fraction of a's and b's in the trace. This is done by
For example, on the input sequence
a, b, a, a, b, b
the resulting feature vector would be (0.4, 0.6).
We then use the K-means clustering algorithm to find the centroids of two clusters based on those feature vectors.
The processor mining function is therefore parameterized as follows:
| Parameter | Value |
|---|---|

| 
|

| 
|
The traces in the input CSV file either have an approximate 30%-70% distribution of a's and b's, or the reverse. The feature vectors can be plotted as follows, with each dot representing the a-b distribution of a single trace.
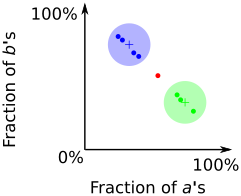
Applying the k-means algorithm, with k=2, will compute two cluster centers, represented by crosses in the above plot.
Definition at line 96 of file KmeansSymbolDistribution.java.
 1.8.13
1.8.13